
NVIDIA 13 日正式发布首款基于全新 Fermi 微架构「 GF106 」绘图核心,针对主流游戏玩家市场的「 GeForce GTS 450 」绘图卡产品,取代 GeForce GTS 250 绘图卡产品,对手将为 Radeon HD 5750 绘图卡。究竟全新 GeForce GTS 450 绘图卡,能否延续效能级 GeForce GTX 460 的强势表现 !? HKEPC 将详细分析全新 GeForce GTX 450 架构设计,并与比自家上代产品及对手同级产品作出比较。
针对主流级游戏玩家市场 --- NVIDIA GF106 GPU
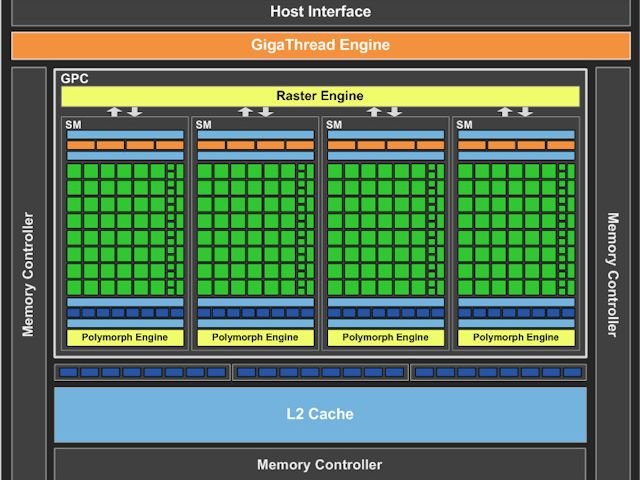
图为全新 GF106 Full Chip
原本预期于去年 12 月推出全新 Fermi 微架构 GPU 的 NVIDIA ,受制于设计过于複杂及制程所限导致良率不足所影响,结果在 DirectX 11 产品线推出时程上一直延宕,根据市调机构 Mecury Research 报告指出, 2010 年第二季 AMD 独立绘图晶片市佔成功超越 NVIDIA ,由第一季 42.1% 大幅上升至第二季 51.1% , NVIDIA 则由 59.2% 跌至 48.8% 。
儘管 NVIDIA 在第二季开始付运新一代 Fermi 微架构 GPU 产品「 GF100 」绘图核心,但主要集中于高阶市场,不仅产量不多而且效能亦未见突出,无法令 NVIDIA 在第二季挽回劣势。不过, NVIDIA 于 7 月中推出的效能级绘图核心「 GF104 」,基于高阶「 GF100 」绘图核心作出了架构上的微调,全新效能级「 GeForce GTX 460 」不仅在效能及售价上均极具杀伤力,而这次发表的主流级「 GF106 」绘图核心,则是基于「 GF104 」绘图核心所简化,推出全新主流级「 GeForce GTS 450 」,能否延续这股强势表现,则成为 NVIDIA 2010 年下半年能否重夺独立绘图晶片市佔龙头的重要关键之一。
GF106 ︰内建 192 个 CUDA Cores
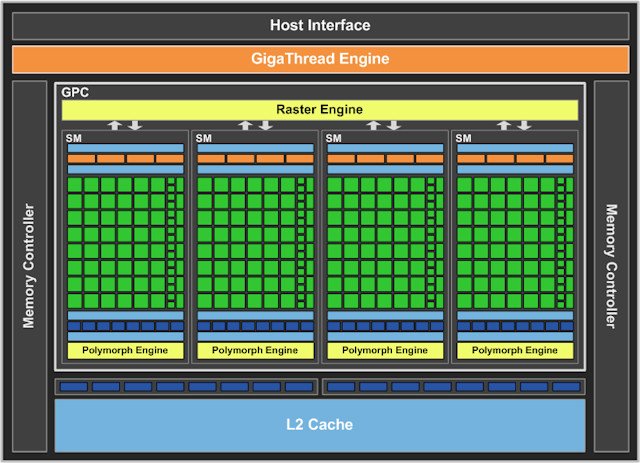
图为 GF GTS 450 绘图于採用经屏蔽的 GF 106 绘图核心
同样地,「 GF106 」绘图核心的架构并不是承袭于高阶「 GF100 」,因为「 GF100 」绘图核心设计是以效能作为优先考虑,并不合符作为主流级绘图核心的高性价比原则,因此「 GF106 」绘图核心是以「 GF104 」作为基础而简化,以符合现今市面上大部份游戏的 Shader 、 Texture 及 Tessellation 使用比例,有关「 GF100 」与「 GF104 」绘图核心的架构差异,可浏览 <<全新 GF104 GPU 核心>> 一文。
根据 NVIDIA 「 GF106 」的绘图核心架构设计,基本上「 GF106 」就是把「 GF104 」割开一半,同样 Fermi 第三代 Streaming Multiprocessor (SM) 架构,「 GF106 」的绘图运算列阵架构 (Graphics Processing Clusters ; GPC) ,由 2 组 GPC 减至 1 组 GPC , GPC 的设计同样具备 4 个 Streaming Multiprocessors (SM) ,每组 SM 内的 CUDA 运算核心数目为 48 个,而非「 GF100 」的 32 个,因此整颗晶片合共拥有 192 个 CUDA 运算核心。
相比上代「 G92 」绘图核心仅 128 个 CUDA Cores ,全新「 GF106 」绘图核心不仅是 CUDA Core 数目上的提升,同时亦不幅改良了平衡运算流程的效率,全新 Fermi 微架构单一週期最高支援 48 warps ,每个 CUDA 运算核心均为 Unified Processor 架构,可执行 Vertex 、 Pixel 、 Geometry 及 Compute Kernels ,更有效地填充数目繁多的 CUDA 运算核心,採用了 GigaThread Engine 架构 , 「 GF106 」 能读取 CPU 的记忆体指令,并进行分支预测把指定的数据先从系统记忆体中读複製到绘图记忆体内。
此外,「 GF106 」的 SM Unit 无论是输入任何大小的向量数据都能以最佳性能运算,并且可在执行 Z-buffer (1D) 或 Texture Acess (2D) 均能完全使用整个核心,每个 CUDA Processor 拥有完整的完全整数运算流水线逻辑单元 (ALU) 和浮点单元 (FPU) ,并实现了全新 IEEE 754-2008 浮点标準,提供融合乘加 (FMA) 指令,包括单及双精度运算。
FMA 指令改善了 MAD 做乘法和单一最后四捨五入动作,但没有损失运算的精密度,令紧密重叠的三角形减少渲染错误的机会。
ALU 经过重新设计,支援所有完全 32Bit Prescision 指令,以符合标準编程语言的要求。整数 ALU 也作出优化 ,令绘图核心更有效地支持 64Bit 和扩展精度运算,更多的指令标準在 「 GF106 」 被加入支援,包括 Boolean 、 shift 、 move 、 compare 、 convert 、 bit-field extract 、 bitreverse 、 insert 及 population count ,因此「 GF106 」与上代「 G92 」的效能差异,绝不是单纯于 CUDA Core 数目差异。